From Langchain’s SQL Agent to Google’s MCP Toolbox for Databases and ADK
Introduction
With the AI space rapidly innovating and expanding, there are constantly new tools and standards emerging to solve complex problems. For a while now, I’ve been running an application based off of Langchain’s SQL agent that allows me to query, in natural language, NHL data that I’ve scraped and stored in BigQuery and more recently, also CloudSQL.
When I initially developed the application, MCP had not yet been introduced and consequently, Google’s MCP toolbox as we know it today had not existed (prior to MCP, it existed as Gen AI Toolbox for Databases). After following the project for the last few months and with Google’s recent release of Agent Development Kit (ADK), I decided it was worth writing a new variant of my application with MCP toolbox and ADK that could easily integrate with agents.
Setting Up MCP Toolbox
Google’s MCP Toolbox aims to heavily simplify the process of setting up an MCP server. There isn’t any code to write - you simply write a YAML file containing the tools, sources, and optional toolsets you want to define and run the server with a Go binary.
Being that I’m leveraging GCP native data services (i.e. BigQuery and CloudSQL), source configuration was extremely simple and thanks to the help of Application Default Credentials (ADC), I didn’t need to store any sensitive information in the YAML file. Here is what my CloudSQL source looks like:
cloudsql-source:
kind: cloud-sql-postgres
project: proj-d-hockey-moonshot-8840
region: northamerica-northeast2
instance: hockey
database: nhl
Moving onto defining tools, I’ll admit this is where I spent most of my time since I’m by no means an SQL expert - which is why I get a lot of value out of my Langchain SQL agent which writes the SQL queries for me. To build the toolbox, I needed to define a list of tools which represented something my server could do. Here is an example of a super simple tool called search-players-by-name :
search-players-by-name:
kind: postgres-sql
source: cloudsql-source
statement: |
SELECT player_id, player_name, current_team FROM players
WHERE player_name ILIKE '%' || $1 || '%'
description: |
Use this tool to get information for a specific player.
Takes a player's name and returns their id, their full name, and the current team they play for.
parameters:
- name: name
type: string
description: The name of the player to search for.
When the agent is trying to figure out how to answer a question, it will look to the tools to see if it can leverage one, or a series of them, to get to the desired answer. Writing clear descriptions is key to provide the agent the necessary context it needs during decision making.
While I was defining the initial set of tools, I had to think about the questions I typically have for my data. For the most part, I’m usually asking questions such as “How many saves has Anthony Stolarz made in each of his last 5 games?” Or “How many goals has Auston Mathews scored against the Ottawa Senators this season?”
Thinking about this drove me to write tools that focused on ensuring the agent would be able to get the team a player played for, given their name, and their performance in a particular set of games, either in a season, or in recent games.
With an initial set of tools created, I deployed this to Cloud Run and then moved onto tying this into ADK.
Hooking in ADK
This was my first time getting hands on with ADK and like the MCP Database toolbox, I found it very straightforward to setup. Again, thanks to ADC, authenticating to the VertexAI API, for Gemini access was simple and didn’t require me to store long lived any API keys.
I was able to build an initial agent with the following 15 lines of code:
from google.adk.agents import Agent
from toolbox_core import ToolboxSyncClient
toolbox = ToolboxSyncClient("https://hockey-mcp-160199654922.northamerica-northeast2.run.app")
# Load all the tools
tools = toolbox.load_toolset()
root_agent = Agent(
model='gemini-2.5-pro',
name='hockey_agent',
description='A helpful assistant that answers questions about hockey.',
instruction='Answer user questions by leveraging the tools you have access to. You are able to use multiple tools to derive the answer.',
tools=tools,
)
On line 4, I use the toolbox client to reach out to my MCP server in CloudRun and then follow to load the tools I defined in the YAML file on line 7. Since I never defined a toolset, I left the function call blank to return all the tools.
Testing the New Application
For the purposes of this blog, I’ll show the tests with the ADK web as I found that visually demos better.
I’ll start with a simple question where it needs to only leverage a single tool:
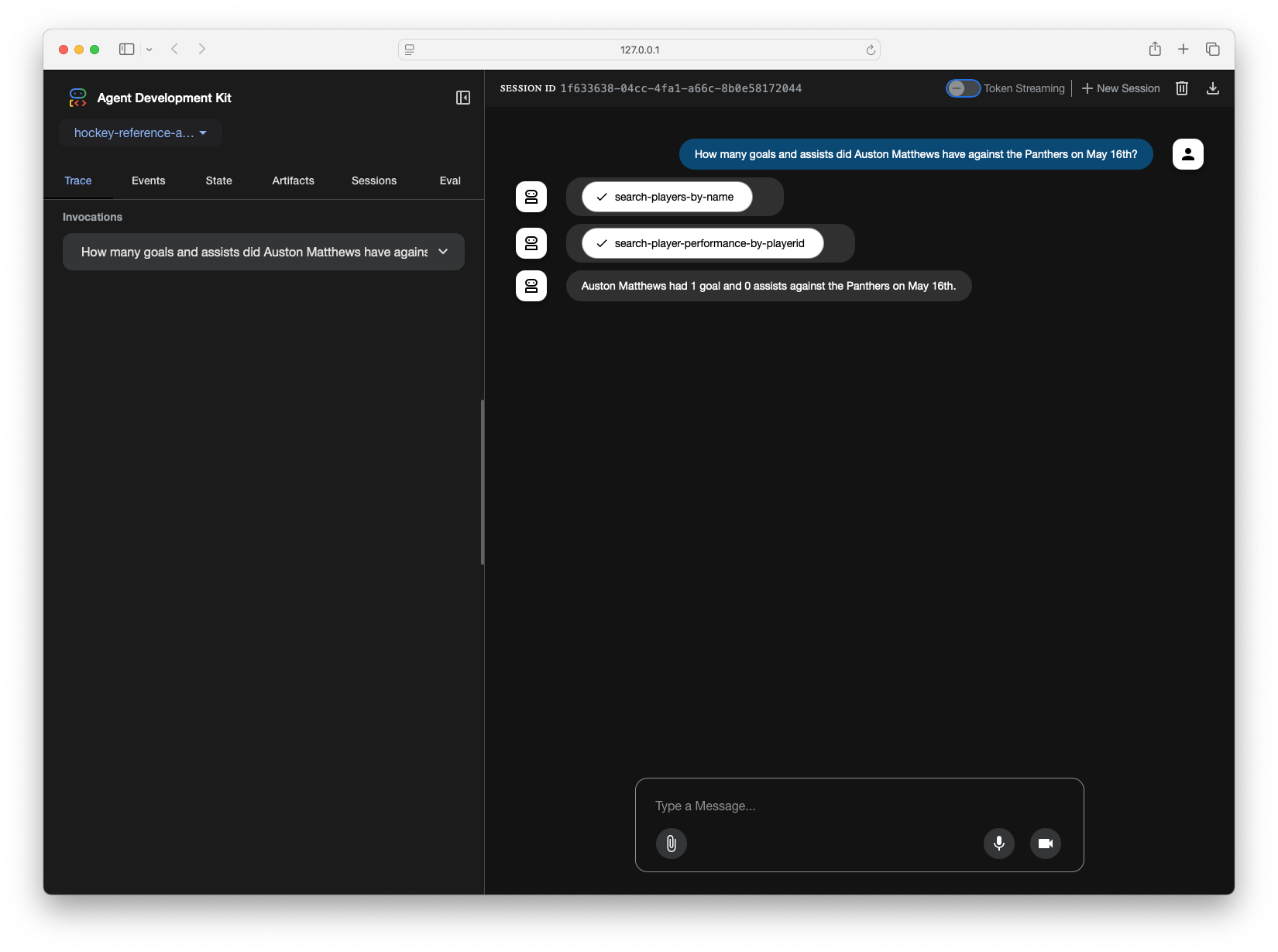
I double checked my own data via SQL and the NHL website just to confirm those numbers were accurate - looks good! Let’s try to up the complexity a bit. I’ll ask it a questions that will require the agent to leverage multiple tools and pass information.
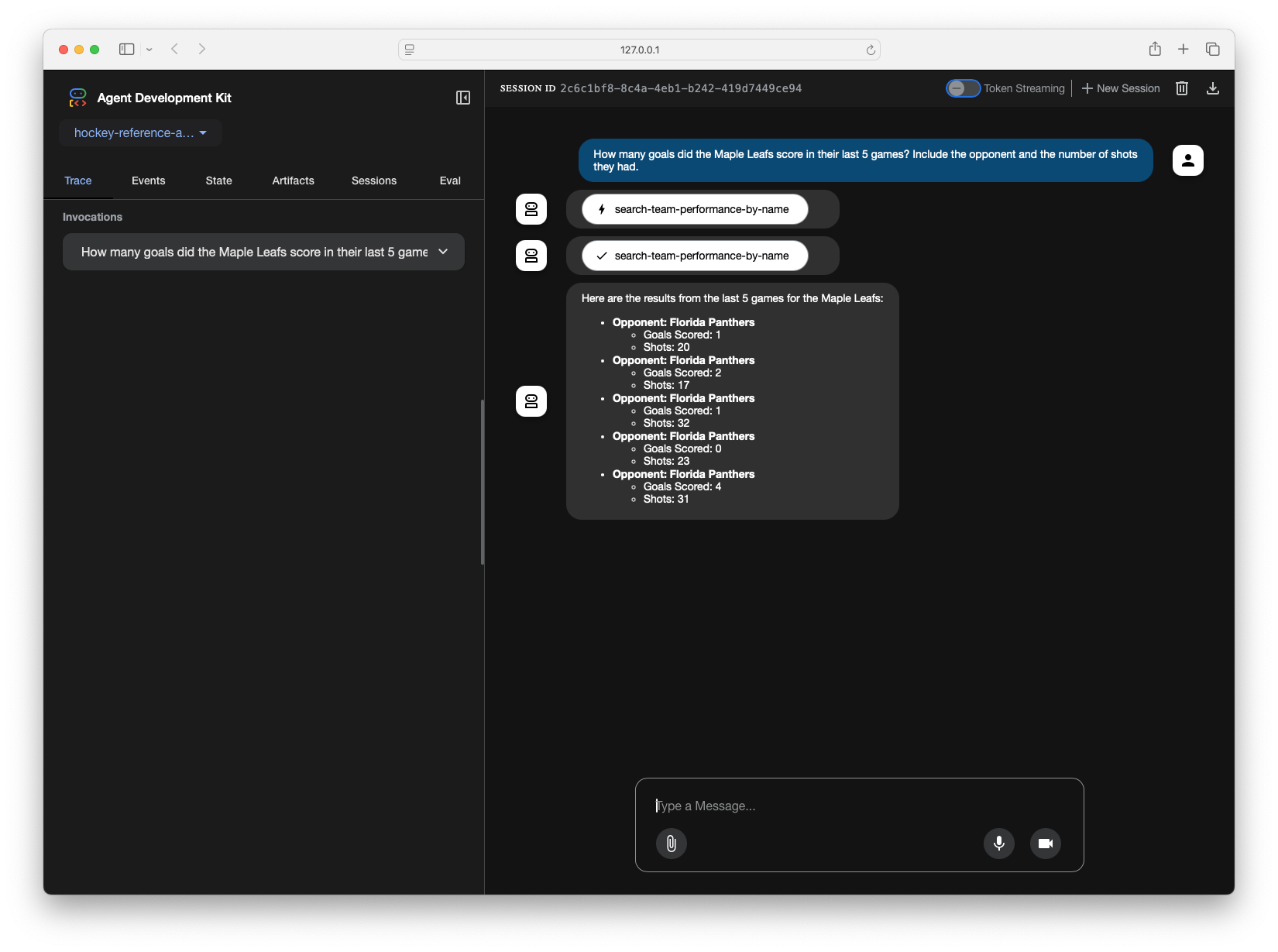
Once again, I double checked this and it checks out! The reason this type of question requires two tool calls is because my database uses player IDs in most tables to represent them, instead of their name. Because of that, I have the dedicated tool to look up a player by their name and return their ID. In all subsequent tools, the tools use the player ID to get additional info.
Tying this Back Into Slack
What I currently really enjoy about my current application is that I can interact with it through a tool I usually have open, Slack. While I could use a Slack MCP client and connect that directly to my MCP server, I potentially lose out on what ADK and the Vertex AI Agent Engine offer. I’m still exploring this further.
Closing Thoughts
I found working with both MCP Database toolbox and ADK extremely easy to work with and more importantly easy to get started. Google has continued to do a great job at integrating new frameworks and standards into their already existing suite natively. I’m looking forward to continue working with both tools and expand this use case.